 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Deep learning is a powerful tool that identifies patterns, extracts meaning from large, diverse datasets, and solves complex problems. However, integrating neural networks into existing compute environments is a challenge that often requires specialized and costly infrastructure.
New software and hardware options will simplify the complexity.
-
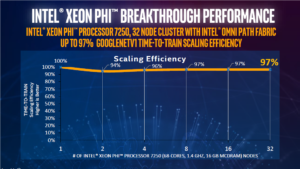
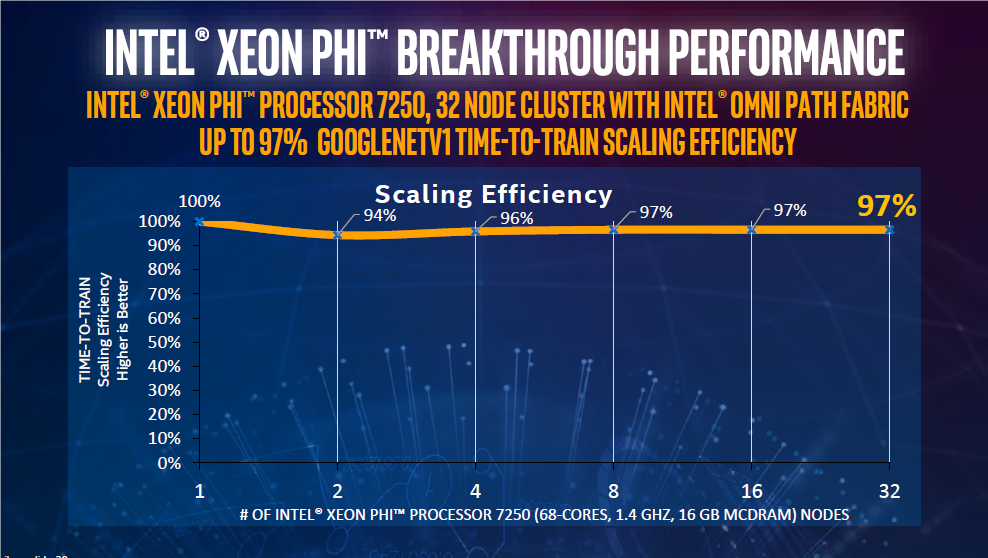
Figure 1. A 32-node cluster based on Intel® Xeon Phi™ processors and Intel® Omni-Path Architecture demonstrated near-linear scaling running a neural network training workload based on Google TensorFlow. Intel® Omni-Path Architecture (Intel® OPA) is well suited to the demands of deep learning, enabling near-linear scalability across large numbers of nodes to provide fast time to results for large problems (see Figure 1).
- Intel® Xeon® Scalable processors provide up to 2.2X higher neural network training performance than previous-generation Intel Xeon processors.[i]
- Intel® Xeon Phi™ processors provide extreme parallelism, and deliver up to a teraflop or more of performance for neural network training, without the inherent latencies of GPUs or other PCIe-connected devices.
- Intel optimized tools, libraries, and frameworks for deep learning provide better performance on Intel architecture than non-optimized software.
A key focus of deep learning implementations is to reduce the time to train the model and to ensure a high level of accuracy. HPC clusters provide a scalable foundation for addressing this need.[ii] However, due to workload characteristics and the compute capabilities of Intel Xeon processors, a high speed, low latency network fabric interconnect is needed to reduce the chance of a performance bottleneck. The fabric must allow all nodes to communicate quickly and effectively, so the servers don’t waste valuable compute cycles waiting to send and receive information.
As part of Intel® Scalable System Framework (Intel® SSF), Intel OPA is designed to tackle the compute- and data-intensive workloads of deep learning and other HPC applications. This high-speed fabric is developed in tandem with Intel compute and storage technologies. The resulting integration helps to resolve many of the performance and cost challenges associated with traditional HPC fabrics.
A Fabric for the Future of AI—and Other HPC Workloads
Deep learning frameworks differ, but the general workflow is the same as it is for many other HPC applications: work the calculation, iterate, then blast out the results to adjacent workloads. During the data sharing stage, a high volume of very small, latency-sensitive messages is broadcast across the fabric.
Breaking Down Barriers in AIAs the interconnect for the Pittsburgh Supercomputing Center’s supercomputer, known as Bridges, Intel® Omni-Path Architecture (Intel® OPA) is already helping to push the boundaries of AI. Bridges compute resources were used to train and run Libratus, an AI application that beat four of the world’s top poker players in a no-limit, Texas Hold ‘em tournament. The performance and scale of Bridges enabled Libratus to refine its strategy each night based on the previous day’s play. One player said it felt like he was “playing against someone who could see his cards.” The victory was about more than bragging rights. Libratus is applicable to other two-player zero-sum games, such as cyber-security, adversarial negotiations, and military planning, so beating humans has profound implications. Read more about the Bridges supercomputer and Intel OPA. |
Intel OPA transmits this traffic with the same 100 Gbps line speed as other high-speed fabrics, but this tells only part of the story. It also includes optimizations that address common bottlenecks.
- Low-Latency, Even at Extreme Scale. Intel OPA provides traffic shaping and quality of service features to improve data flow and prioritize MPI traffic. These advantages help to reduce latency by up to 11 percent versus EDR InfiniBand, with up to 64 percent higher messaging rates.[i]
- Better Price Performance. Intel OPA is based on a 48-port chip architecture (versus 36-port for InfiniBand). This reduces the number of switches, cables, and switch hops in medium to large clusters, which provides both cost and performance advantages.
- Improved Accuracy and Resilience. Unlike InfiniBand, Intel OPA implements no-latency error checking, which improves data accuracy without slowing performance. It also stays up and running in the event of a physical link failure, so applications can run to completion, a crucial advantage for lengthy training runs.
Tight Integration Throughout the Stack
Tight integration among Intel OPA and the other components defined by Intel SSF provides additional value. For example, Intel Xeon Scalable processors and Intel Xeon Phi processors are available with integrated Intel OPA controllers to reduce the cost associated with separate fabric cards.
Intel also developed and tested Intel OPA in combination with our full HPC software stack, including Intel® HPC Orchestrator, Intel® MPI, the Intel® Math Kernel Library for Deep Neural Networks (Intel® MKL-DNN), and the Intel® Machine Learning Scaling Library (Intel® MLSL). This integration helps to improve performance and reliability. It also reduces the complexity of designing, deploying, and managing an HPC cluster.
A Faster Road to Pervasive Intelligence
Learn more about Intel SSF benefits for AI and other HPC workloads at each level of the solution stack: compute, memory, storage, fabric, and software.AI is still in its infancy. Tomorrow’s neural networks will dwarf those of today. The mission of Intel OPA and the full Intel SSF solution stack is to make the computing foundation for this growth as simple, scalable and affordable as possible, not only for AI, but for all HPC workloads. This will help to ensure that front-line innovators have the tools they need to support their core mission—transforming the world through deep, pervasive intelligence.
[1] For details, see https://www.intel.com/content/www/us/en/processors/xeon/scalable/xeon-scalable-platform.html
[2] Not all deep learning frameworks are optimized to run efficiently on HPC clusters. Intel is working with the vendor and open source communities to resolve this issue and to lay the foundation for increasingly large neural networks acting on petabyte-scale datasets.
[3] For details, see https://www.intel.com/content/www/us/en/high-performance-computing-fabrics/omni-path-architecture-performance-overview.html

























































